
멀티스레드를 이용하는 서버 엔진을 설계해보면서 각 유저 세션의 송신버퍼(SendBuffer)를 불가피하게 Lock으로 관리해야 했다. 현재 구조에서는 문제가 없지만 나아가 Deadlock이나 Lock에 의한 성능 저하가 걱정되어 락 프리(Lock-Free) 알고리즘에 대해 공부해보았고 이를 정리해보았다.
락 기반 알고리즘의 문제점
Mutex, Semaphore나 를 이용한 Lock을 통해 멀티스레드를 관리할 때에는 Lock을 획득하지 못한 스레드는 Lock을 획득한 스레드가 해당 Lock을 Release 할때까지 대기상태에 머물러야 한다는 단점이 있음. 또 DeadLock과 같은 예상하지 못한 문제가 발생할 수도 있다.
한마디로 일반적으로 Lock 사용 시 공유 메모리에 접근하는 멀티쓰레드가 많아질수록 성능이 오히려 떨어지게 되는 문제점 발생 한다는 뜻이다.
락 프리(Lock-Free) 알고리즘
락 프리(Lock-Free)란? 여러 개의 쓰레드에서 동시 호출하더라도 특정 단위 시간에는 적어도 한개의 호출이 완료되는 알고리즘이라고 정의할 수 있다. 즉, 다른 쓰레드의 상태에 상관 없이 적어도 하나의 쓰레드의 호출은 완료된다는 뜻이다.
알고리즘은 다음과 같이 나뉘는데
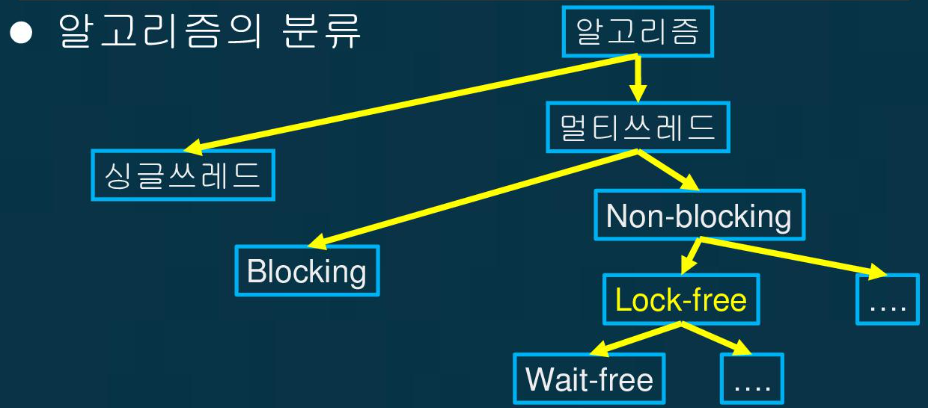
당연한 말이지만, 그림에서 알 수 있듯이 기본적으로 Non-blocking이 보장되어야 한다. 또 Lock-Free에서 나아가 Wait-Free 알고리즘도 존재하는데, 항상 어떤 스레드도 Wait을 하지 않고 모든 쓰레드가 실행 중이며, 해당 쓰레드의 CPU 사이클 내에 어떤 작업이 완료될 것이라고 보장된다. 즉, 다른 쓰레드와 상관 없이 모든 쓰레드가 delay없이 공유 메모리에 접근할 수 있다는 의미이다.
Lock Free 알고리즘의 가장 기본적인 원리는 매우 간단하다. 공유 메모리 변수의 값을 일단 변경하고 해당 값이 맞는지 확인하는 방법이다. 만약 값을 변경하는 동안 다른 스레드에서 간섭이 있었는지를 확인하고, 만약 간섭이 있었다면 그에 대한 처리를 해주면 되고 간섭이 없었다면 제대로 작동하게 된 것이 된다.
여기에 사용되는 연산이 CAS(Compare And Swap - 읽고 비교하고 쓰는) 연산으로, 최근 거의 모든 프로세스에서 CAS 연산을 단일 연산으로 Atomic하게 동작하도록 지원하고 있다.
C++11 std::atomic의 CAS 함수의 원형을 예시로 살펴보면 이를 더 자세히 알 수 있다.
bool compare_exchange_weak(T& expected, T desired);총 3개의 인자가 사용되는데, 작업할 대상 메모리의 위치(atomic 변수), 예상하는 기존 값(expected), 새로 설정할 값(desired). CAS연산은 atomic 변수 위치에 있는 값이 expected와 같은 경우에 desired로 변경하는 단일 연산이다. 만약 값을 변경하면 true를 리턴하고, 변경하지 못하면 false를 리턴한다.
그렇다면 CAS 연산이 어떻게 Lock-Free 알고리즘에 사용될 수 있는 것일까? 만약 여러 스레드가 동시에 CAS연산을 사용해 한 변수의 값을 변경하려고 하면, 스레드 가운데 하나만 성공적으로 값을 변경할 것이고, 다른 스레드들은 모두 실패한다. 이때 CAS 연산에 실패한 스레드는 대기상태에 들어가는 대신, 값을 변경하지 못했지만 다시 시도하거나 다른 방법을 취하는 등, 여러가지로 구현할 수 있다.
말이 어려우니 예시를 들어보면 멀티 쓰레드에서 다음 함수를 모두 돌고 있다고 가정해보자.
atomicVariable은 전역변수로 모든 쓰레드에서 접근가능한 변수라고 가정해보고 모든 쓰레드에서 해당 값에 접근하여 해당 값을 nullptr로 바꿀려고 하는 상황을 생각해보자..
void threadTask()
{
Node* expected = atomicVariable;
while(atomicVariable.compare_exchange_weak(expected, nullptr) == false);
// do it something
}이때, expected에 atomicVariable을 대입하고 CAS연산을 통해 atomicVariable과 expected를 비교해준다. 이 동작이 다소 이상해보일 수 있겠지만, 만약 Thread A에서 expected에 atomicVariable을 대입한 후에 컨텍스트 스위칭이 일어나서 Thread B가 expected에 atomicVariable을 대입하고 while문을 돈다고 해보자. 이때 Thread B에서는 expected와 atomicVariable이 같으므로 문제 없이 while문을 빠져나오고 atomicVariable에는 nullptr이 들어가 있게 된다.
하지만 다시 Thread A로 컨텍스트 스위칭이 일어나게 되면 현 시점에서의 atomicVariable은 nullptr이므로 둘은 같지 않아 while문을 빠져나올 수 없게 된다. 만약 Thread C, D, E 등 여러 쓰레드가 있었어도 결국 Thread B만 CAS 연산에 성공하게 되고 나머지 Thread는 값이 바뀐 atomicVariable과의 CAS연산에 실패하게 된다.
이처럼 여러 쓰레드가 접근했을 때 적어도 한 쓰레드는 CAS연산에 성공하게 되고 다른 쓰레드에서는 이미 값이 변했기 때문에 while문을 돌면서 다시 CAS연산이 성공할 때까지 자신의 차례를 기다릴 수 있게 된다. 이처럼 CAS 연산을 통해 Lock-Free 알고리즘을 구현할 수 있음을 알 수 있다!
락 프리 기반 자료구조의 장단점
락 프리 자료구조를 사용하는 주된 이유는 최대한의 동시성 프로그래밍을 하기 위해서이다. 락 기반의 컨테이너는 다른 쓰레드가 락을 사용하여 다른 쓰레드들이 기다려야 한다. 하지만 락 프리 자료구조는 항상 어떤 쓰레드가 어느 정도 실행을 할 것이라 기대할 수 있다. (적어도 하나의 쓰레드는 연산에 성공하므로)
또한 락 기반의 프로그래밍은 오류로 인해 락을 가지고 있는 쓰레드가 강제 종료되면 다른 쓰레드는 영원히 블록된다. 락이 없는 프로그래밍은 해당 오류 쓰레드의 정보만 손실될 뿐 다른 쓰레드는 여전히 실행 가능하다!
하지만 락이 없는 프로그래밍을 설계하기 위해서 일단 복잡한 알고리즘이 동반된다. 또한 메모리 재사용이 어려워진다. 이는 ABA 문제와 연관되어 있다.
ABA 문제
CAS 연산에서는 위에서 보였듯이 변수값이 아니라 해당 변수의 주소값을 비교하여 연산을 진행하게 된다. 이때 주소값을 통해 비교하기 때문에 해당 메모리 주소에 있는 변수가 원래 변수와 다르더라도 같다고 생각하고 연산을 진행하게 되는 것을 ABA 문제라고 한다.
그림은 Lock-Free 알고리즘이 적용된 스택을 사용한 예시이다.
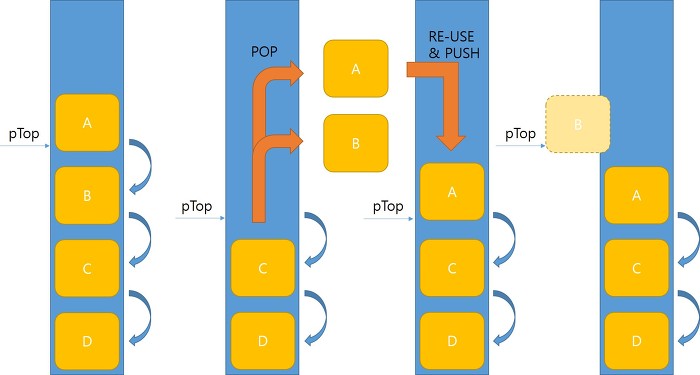
Thread 1이 Pop하기 위해 가장 맨위 노드인 pTop 노드를 A, 그리고 그 다음 노드를 B(A를 Pop하고 B를 Top으로 설정하기 위해 저장)라고 저장했다고 하자. 이때 다른 Thread 2에서 A랑 B를 둘 다 Pop해 버리고 해제까지 완료했지만 A와 같은 주소 값을 가진(주로 메모리 풀을 이용하다 보면 이런 경우가 자주 발생할 것이다..), 즉 A의 주소값을 재사용하여 만들어진 새로운 A를 Push했다고 해보자. Thread 1로 다시 돌아왔을 때 pTop이 A인 것을 확인하고(실제 다른 변수지만 메모리 주소 값이 같은..) 그 다음 노드 B를(이미 해제되어 버린) 스택의 Top으로 설정하게 되고, 이는 이미 해제되어 버린 B를 Top으로 하게 되어 문제가 발생한다.
이는 단순 메모리의 주소 만으로는 자료구조 데이터의 일관성을 보장하기 힘들다는 점에서 시작한다. 따라서 단순 주소값 비교가 아닌, 다른 추가적인 방법을 통해 일관성을 보장해야 한다.
ABA 문제 해결
1. DCAS (Double compare-and-swap)
CAS를 두번 체크하는 것이다. 이때 처음 CAS는 주소값을, 두번째 CAS는 추가적인 검증을 위한 데이터를 두어 CAS 연산을 해주는 것이다. 예를들어 보편적으로는 데이터가 Pop이 된 순서(PopCount)를 추가적인 검증 수단으로 둘 수 있다.
void Pop()
{
Node* top = head;
int pop_count = popCount;
while(head.compare_exchange_weak(top, top->next) == false ||
popCount.compare_exchange_weak(pop_count, pop_count+1) == false);
// do something
}그런데 다음과 같이 비교하면 결국 두번의 원자적인 연산이므로, 둘을 합친 연산 자체는 원자적이지 않게 된다.
따라서 실제로는 Node 자체에 해당 정보를 추가적으로 집어 넣어 주소값(64비트) + 추가적인정보(64비트)를 통해 총 128비트의 CAS연산을 해주는 InterlockedCompareExchange128을 이용하여 둘을 한번에 비교해주면 된다!
2. Hazard Pointer
해제하면 안되는 포인터를 Hazard Pointer라고 하는데, 각 쓰레드에서 사용중인 포인터를 Hazard Pointer에 등록하여 해당 포인터들을 메모리를 즉시 해제하지 않는 방식이다. 이렇게 되면 적어도 해당 포인터를 잡고 있는 쓰레드에서 Hazard Pointer 리스트에서 해당 포인터를 삭제하기 전까지는, 메모리가 해제되지 않기 때문에 메모리 재사용은 일어나지 않게 된다.
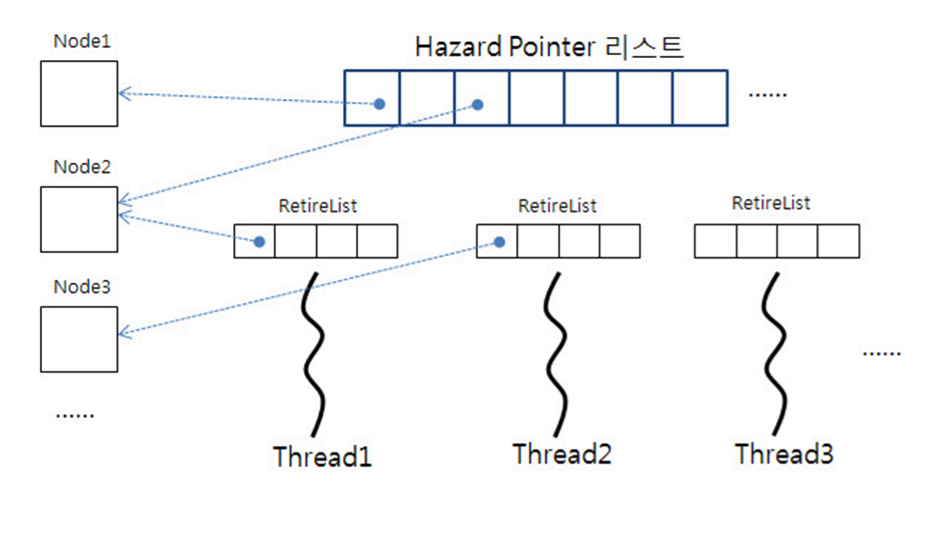
그림과 같이 Hazard Pointer 리스트를 Lock-Free List로 만들어 두고, 각 스레드에서 사용중인 포인터들을 해당 Hazard Pointer 리스트에 저장해둔다. 그리고 각 쓰레드에서는 각자의 TLS로 RetireList라는 리스트를 갖게 되는데, 이는 당연히 자신의 쓰레드에서 Pop을 한 포인터 들을 저장하는 리스트이다. 이렇게 은퇴(?)된 포인터들을 RetireList에 모아두고 해당 RetireList에 저장된 포인터들이 Hazard Pointer 리스트에 포함되어 있는 지 확인한 후에, 포함되지 않았다면 해제를 하고 포함되었다면 당장은 해제하지 않는다.
물론.. Pop할때마다 RetireList와 Hazard Pointer 리스트를 비교하면 부하가 심할 것이므로.. 일정량 모은 후에 비교해주도록 해야한다.
사실 GC가 작동한다면.. ABA 문제는 발생하지 않는다. 해당 메모리를 다른 스레드에서 로컬 변수로 사용중인 것을 GC 자체에서 알고 있기 때문에 메모리로 반환이 되지 않아 재사용되지 않기 때문이다.
뭔가.. 게시글 하나로 복잡한 락 프리 알고리즘을 설명할려고 했더니 많은 부분들이 생략된 느낌이다... 조금 더 추가적인 내용들과 실제 락 프리 알고리즘을 적용한 구현 내용은 다음 게시글에 정리해서 올려보도록 하겠다
'서버' 카테고리의 다른 글
| [C++] 메모리 풀(Memory Pool) 구현 (1) | 2024.09.24 |
|---|---|
| [서버구조분석] NodeJS 프레임워크 기본구조 분석( 부제 : 멀티스레드 vs 싱글스레드 ) (0) | 2024.04.11 |
| [서버구조분석] Spring 프레임워크 기본구조 분석 (0) | 2024.03.26 |
| 소켓 통신 프로그래밍(2) (1) | 2024.03.06 |
| 소켓 통신 프로그래밍 정리(1) (1) | 2024.03.05 |